我發現,我跟 AI 大神用著同一套筆記法
Andrej Karpathy 用 LLM + Obsidian 建知識庫的方法,跟我這幾個月搭的系統核心邏輯幾乎一樣,這篇文章就來分享這套流程怎麼走,以及我與他系統之間的差異。

Andrej Karpathy,OpenAI 共同創辦人之一,前 Tesla AI 總監,AI 圈大概沒有人不認識他。他最近發了一篇文,講他怎麼用 LLM 建個人知識庫——把原始資料丟進去,讓 AI 幫你編譯成結構化的 wiki,整個過程在 Obsidian 裡面操作。這篇文在社群上傳得很廣。
我讀完的反應是:這根本是我每天在做的事。
跟我這幾個月在 Obsidian 裡面搭的系統,核心邏輯幾乎一樣。我稍微比對了一下,看看哪裡重疊、哪裡不同、有什麼可以互相借鑑的。
這套系統如何運作
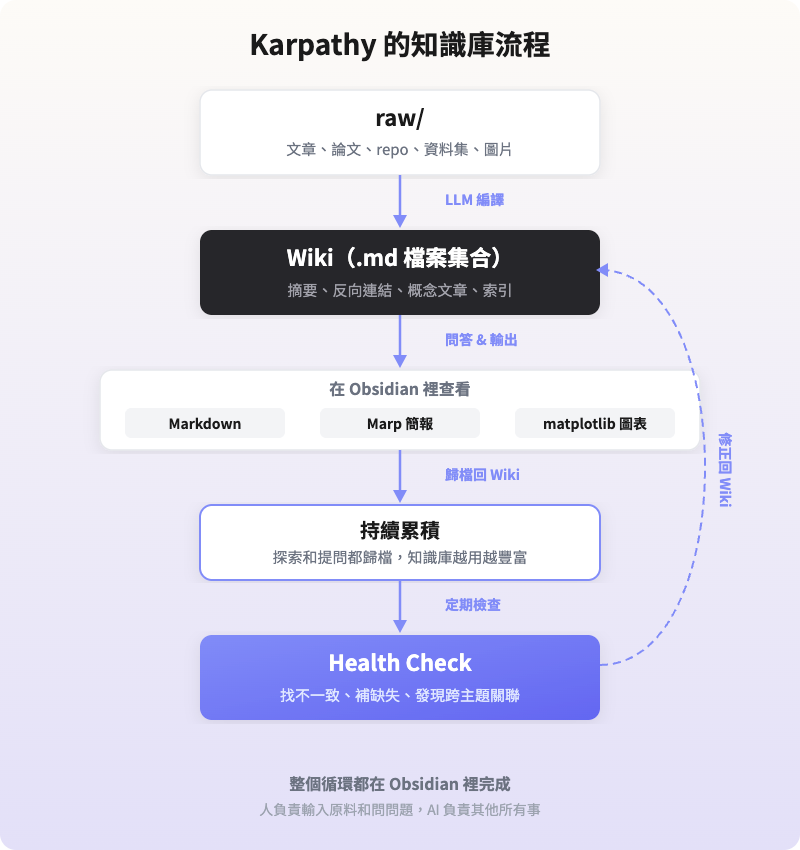
先簡單說一下 Karpathy 的整套流程。他把原始文件(文章、論文、repo、資料集、圖片)全部索引到一個 raw/ 目錄,然後讓 LLM 逐步「編譯」成一個 wiki——以目錄結構組織的 .md 檔案集合,包含摘要、反向連結,並將資料歸類為概念、為每個概念撰寫文章、再把它們全部串連起來。
他用 Obsidian 當「前端」,在裡面查看原始資料和已編譯的 wiki。重要的是:wiki 裡的所有資料都由 LLM 負責撰寫和維護,他幾乎不會直接動它。
當 wiki 夠大之後,就可以對著它問各種複雜問題,讓 LLM agent 去研究、找答案。他不需要複雜的 RAG,LLM 自動維護索引檔案和各文件的簡短摘要,就能找到相關資料。輸出則是 markdown 檔案、Marp 簡報、matplotlib 圖表,產出會歸檔回 wiki,讓知識庫越用越豐富。
他還會對 wiki 跑「健康檢查」——找不一致的資料、透過網路搜尋補缺失資訊、發現跨主題的有趣關聯,逐步提升整體資料的完整性。
高度雷同的地方
Obsidian 當前端,LLM 當後端。
Karpathy 說他用 Obsidian 當 IDE 前端,查看所有資料。wiki 裡的內容「全部由 LLM 負責撰寫和維護,我幾乎不會直接動它」。
我也是。我的 Cards、索引、Content 裡面大部分的整理和初稿都是 Claude 在寫。我負責輸入想法,做最終決策,中間的分類、擴寫、排版,交給 AI。
原料 → 加工 → 成品的管線。
他有一個 raw/ 目錄,把文章、論文、repo 全部丟進去,然後讓 LLM「編譯」成一個結構化的 wiki。我的做法是 inbox → cards,東西先進暫存區,AI 幫我整理成想法卡片、分類到索引,最後組合成發文內容。
名字不同,路線一樣:人丟原料,AI 做加工與分類。
另外,這邊提到一個重要的觀念——索引。
當Token越來越貴,我們就要思考如何在同個時間,讓Token效率最大化
他說「LLM 很擅長自動維護索引檔案和各文件的簡短摘要」,不需要複雜的 RAG,讀索引就能找到相關資料。
我用的也是索引頁。每個主題一個索引,上面寫描述和脈絡。AI 讀一個索引就能理解整個主題底下有什麼,比標籤省 Token 、也比 RAG 精準,因為有時候你的一個想法,不一定包含該主題的關鍵字。
他說「我自己的探索和提問,都會持續累積在知識庫裡」。我抱持一樣的理念——卡片越多,AI 能引用的素材越豐富;Skill 越多,重複任務越自動化。這套系統是會長大的,用越久越快。
一些不同的地方。
比對之後發現,有幾個面向是我的系統有做、但 Karpathy 沒有提到的。
AI 工具箱的分層設計。
Karpathy 只講了「讓 LLM 做事」,但沒有講怎麼讓它做得穩定、可重複。
我把給 AI 用的資源拆成四層:Refer(參考素材)、Template(模板與準則)、Prompt(單次指令)、Skill(多步驟工作流)。這樣 AI 每次執行同一件事,品質是可控的。
想法跟知識的分流。
他把所有原始資料都叫 raw/,不分來源。但我覺得「你自己的想法」跟「別人的資訊」後續的流向完全不同——你的想法會變成觀點卡片,別人的資訊會變成知識筆記。混在一起處理,後面很難用。
我將資訊根據來自他人還是自己,分成「外部資訊」與「內部資訊」,這樣才不會你請AI幫你寫的時候,混了一堆別人的觀點。
創作者的產出管線。
他的系統是研究導向的——讀進來、問出去。但我是內容創作者,所以我多了一整層「產出」的管線:cards 挑素材、組合擴寫、多平台發布。知識庫對我來說是「發文的素材庫」,對他來說比較像「研究的百科全書」。目的不同,架構自然不同。
從他的文章學到的
反過來,Karpathy 有一個做法我覺得很值得借鑑。
Health Check——幫知識庫做健康檢查。
這是我覺得最有啟發的一點。他會定期讓 LLM 對整個 wiki 跑「體檢」:找不一致的資料、透過網路搜尋補缺失資訊、發現跨主題的有趣關聯。
我的系統目前偏「流動型」——東西進來、分類、產出,一直往前走。但很少回頭看整體。哪些索引太久沒更新了?哪些卡片之間的觀點其實互相矛盾?哪個主題明明很重要但只有一兩篇淺層筆記?這些問題,應該定期讓 AI 掃一遍。
結語
Karpathy 的系統是研究者視角,我的是創作者視角,但核心理念殊途同歸:AI 已經徹底改變了知識管理的方式。你不需要自己整理所有東西,你需要的是給 AI 一個它能持續工作的環境。
這就是我所說的「AI Native」知識管理工作區——從一開始就為 AI 協作設計的架構,而非事後把 AI 硬塞進傳統筆記流程。
下一篇,我會把整套工作區的架構攤開來講:資料夾怎麼建、資訊怎麼流動、AI 在哪些節點介入。如果你也想建立自己的 AI Native 工作區,可以期待一下我的下一篇文章。

Pan
用AI Agent與多元能力,用興趣打造能變現的一人事業
Newsletter
訂閱電子報,不錯過真實的 AI 實戰心得
我會分享 AI Agent、內容工作流、工具實作與一人事業的踩坑筆記。


